概要
JuryArenaは、実際に使用しているプロンプトを用いて、複数のLLMをアリーナ形式で比較できるオープンソース評価ツールです。
正解や採点基準を事前に定義することなく、実務タスクに近い形でモデルの応答品質を相対的に比較できます。
- 実際に使用しているプロンプトを評価に利用できます。
- 複数モデルを同一条件下でアリーナ形式により自動比較できます。
- LLM as a Judge によるペアワイズ判定で、主観的品質を相対評価できます。
- RAG、エージェント、チャットボットなど実務ユースケースを直接評価できます。
- 評価の全過程はトレースとして保存され、判定内容を後から確認できます。
- 正解データを設計することなく、実務ベースで継続的なモデル選定が可能です。
アリーナ形式
アリーナ形式とは、複数の参加者をペアで対戦させ、その勝敗結果をもとにレーティングを更新し、相対的な順位を算出する一般的な評価方式です。
JuryArenaでは、このアリーナ形式をLLM評価に応用し、モデル出力同士を直接比較することで相対的な品質を算出します。

- 同じプロンプトで1対1の対戦(例:LLM A vs LLM B)
- 勝敗でレーティング変動
- ペアを変えて対戦を繰り返してランキング作成
データセット
JuryArenaには、評価をすぐに体験できるサンプルデータ(テンプレート)が含まれています。 独自のデータを用意しなくても、そのまま評価を開始できます。
データセットは、基本的に以下の形式で構成されます。
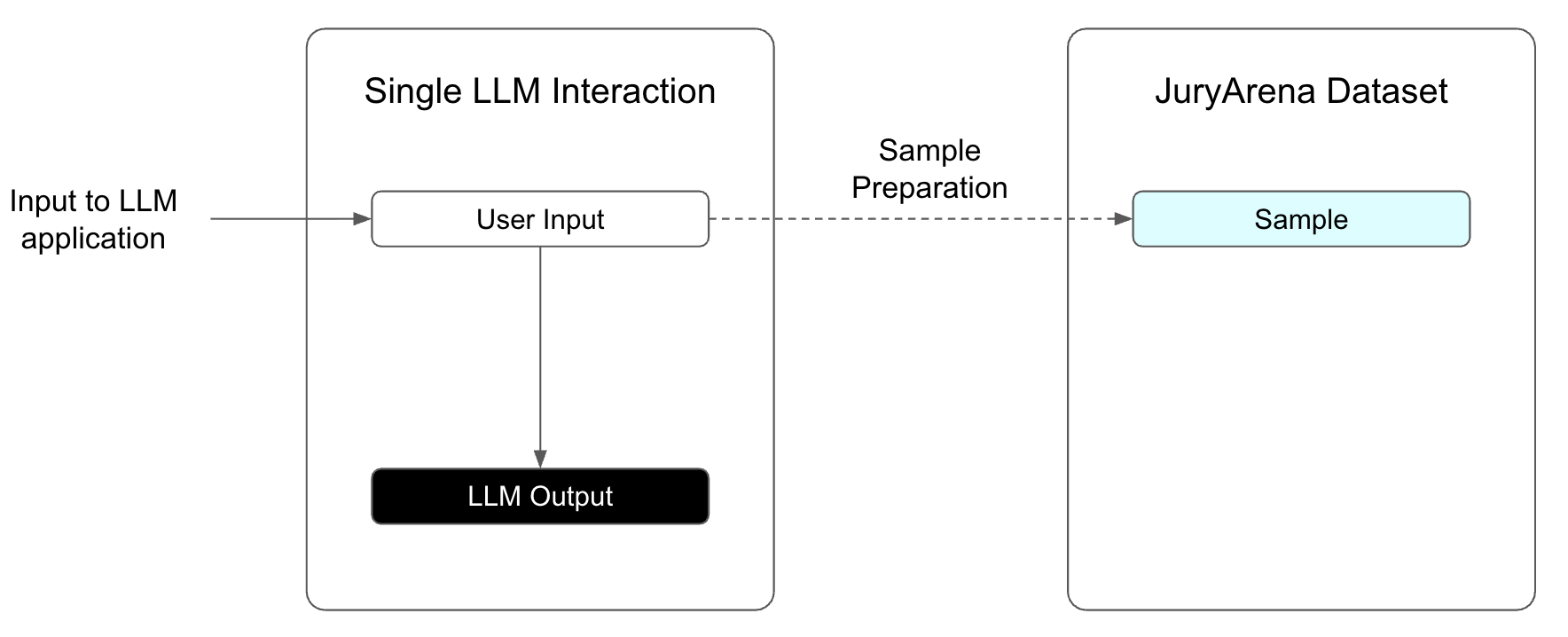
シングルターン
入力プロンプトから smaple を作成します。 詳細については、データフォーマット を参照してください。
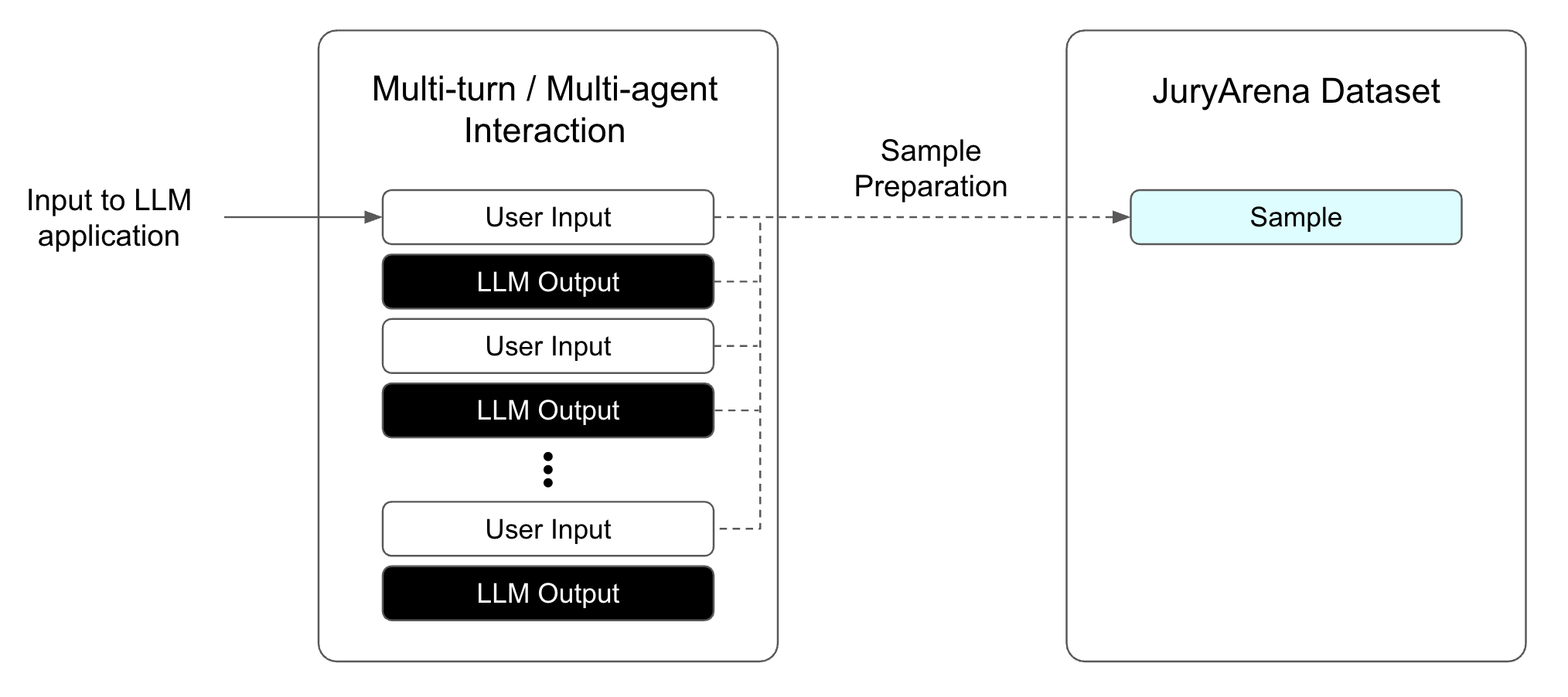
マルチターン
一連の会話履歴をまとめて 1つのSample として扱います。 会話履歴全体をコンテキストとして入力し、最後のUser Inputに対するLLMの応答品質を評価します。
例
json
{
"input": {
"messages": [
{
"role": "user",
"content": "Write a haiku about programming."
},
{
"role": "assistant",
"content": "Silent lines of code\nLogic flows in quiet streams\nNight glows with blue light."
},
{
"role": "user",
"content": "Make it more hopeful."
}
]
},
"usage_output": null
}次のステップ
クイックスタート に進んでセットアップを始めましょう。